AI Development
Engineering Management
Guides
The AGENTS.md Standard: How to Write an AI Agent Operating Manual for Your Repository
Codse Tech
March 5, 2026
AI coding agents are writing real production code now. But most teams learn the hard way that an agent without context is just a fast way to create technical debt.
That's where AGENTS.md comes in. It's a single file that tells an agent how your repository works: what to build, what not to touch, and how to validate its own output.
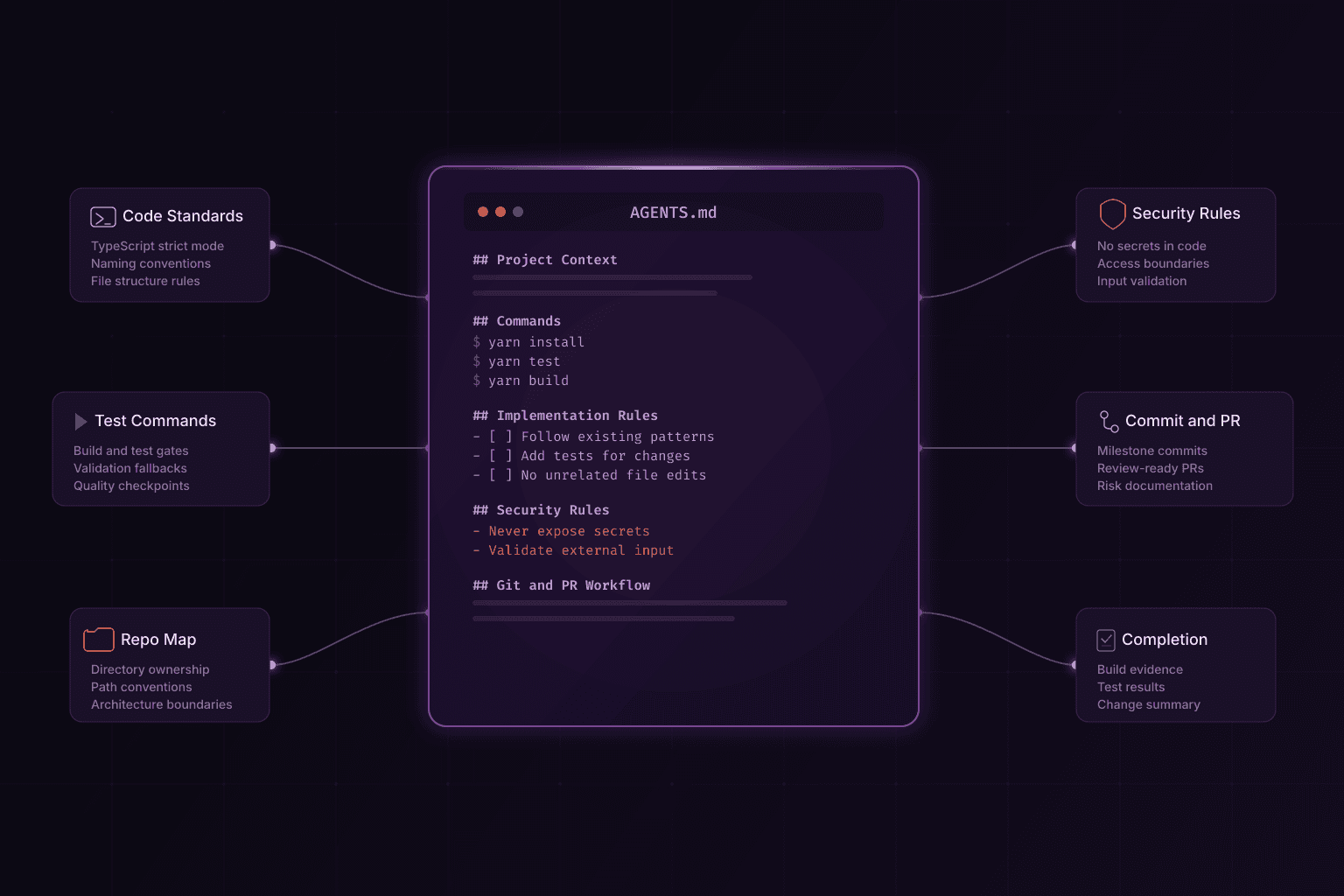
What is AGENTS.md?
AGENTS.md is a machine-readable operating manual for AI development agents.
In practice, the file helps an agent answer five questions before it writes anything:
- What is this project and what does it build?
- Which files and folders matter most?
- How should code changes be implemented and validated?
- What safety and compliance constraints apply?
- What does the pull request and review workflow look like?
Without these answers, agents guess. And agents that guess create PRs that need heavy rewriting.
Why the AGENTS.md standard is becoming essential in 2026
Most teams using agents now work in a hybrid model: humans set direction, agents execute scoped tasks, reviewers check the output. The weak link is usually unclear repository rules. An agent can't follow conventions it doesn't know about.
A good AGENTS.md fixes this by giving agents the right starting point. Generated code follows existing patterns because the file says what those patterns are. Agents skip trial-and-error discovery because commands and structure are documented. Security rules are explicit. PR expectations are clear. New engineers benefit from the same source of truth.
For teams running AI agent development at scale, this file is the difference between agents that produce review-ready code and agents that produce cleanup work.
Required sections in a production-ready AGENTS.md
The file needs to be specific to your repository, not generic advice. Here are the sections most teams should include.
1) Repository purpose and architecture map
Start with a short explanation of the product and system boundaries. Then map core directories.
Example structure:
src/appfor routes and pagessrc/componentsfor UI primitivessrc/libfor shared business logiccontent/for MDX contentscripts/for build and maintenance tooling
Without this, agents will put files wherever seems reasonable to them, which is rarely where you want them.
2) Development environment and commands
List canonical commands for install, run, test, and build. Include exact package manager requirements.
Example command set:
yarn installyarn devyarn buildyarn test
If linting is temporarily broken, say so and document what the agent should run instead. Don't leave it to figure out on its own.
3) Coding conventions and editing constraints
Define language-level standards and style boundaries, such as:
- TypeScript strictness requirements
- naming conventions for files and exports
- comment policy
- prohibited dependencies or patterns
- accessibility expectations for frontend changes
Be explicit about editing constraints, including rules for destructive git operations and changes in unrelated files.
4) Security and compliance guardrails
This is where you draw hard lines. Common ones:
- never commit API keys or secrets
- avoid logging sensitive user data
- enforce authorization checks on protected routes
- require schema validation for external inputs
- follow compliance constraints for regulated domains
If you're building AI features in regulated sectors, these guardrails work well alongside MCP server development where you can control exactly which tools and data the agent can access.
5) Pull request and commit workflow
Define what “done” means for autonomous execution.
Recommended rules:
- keep commits focused by milestone
- include test/build evidence before completion
- summarize behavior change and risk areas in PR descriptions
- call out known limitations and follow-up tasks
The difference between a PR you can review in 10 minutes and one you need to rewrite often comes down to whether these rules existed.
AGENTS.md template for software teams
Use this baseline and customize by stack:
# AGENTS.md
## Project Context
- Product: <what this repository builds>
- Primary stack: <frameworks/languages>
- Core goal: <business or technical objective>
## Repository Map
- <path>: <purpose>
- <path>: <purpose>
## Commands
- Install: `<command>`
- Dev: `<command>`
- Test: `<command>`
- Build: `<command>`
## Implementation Rules
- Follow existing architecture and naming conventions.
- Make minimal, scoped changes.
- Add or update tests for behavior changes.
- Do not modify unrelated files.
## Security Rules
- Never expose secrets in code, logs, or docs.
- Validate external input before processing.
- Respect authorization boundaries.
## Git and PR Workflow
- Use focused commits for each milestone.
- Run required validation commands before handoff.
- Document risks, assumptions, and test coverage in PR summary.
Common mistakes that make the file useless
We see these a lot, even from experienced teams.
| Mistake | Why it breaks workflow | Better approach |
|---|---|---|
| Generic instructions only | Agent cannot map rules to repository reality | Add concrete file paths, commands, and ownership boundaries |
| Missing validation commands | Agent stops without deterministic quality checks | Define exact build/test gates and fallback rules |
| No security section | Increased risk of unsafe code and accidental data exposure | Add explicit secret handling and permission rules |
| Contradictory guidance | Agent behavior becomes inconsistent between runs | Keep one canonical source and remove outdated rules |
| No commit/PR expectations | Handoffs require heavy manual cleanup | Enforce milestone commits and review-ready summaries |
Implementation checklist
If you're rolling this out across repositories, here's the sequence that works:
- Audit existing build, test, and release commands.
- Write repository map and architecture boundaries.
- Add language-specific coding rules.
- Add security and compliance constraints.
- Define commit and pull request quality bars.
- Run a pilot task with an agent and review outcomes.
- Iterate the file based on real execution logs.
The file should change as your project changes. If your build process or architecture shifts, update it.
Governance model for engineering organizations
The file works best when someone actually owns it. If nobody is responsible for keeping it accurate, it rots fast.
Here's a lightweight ownership model:
| Role | Responsibility |
|---|---|
| Engineering lead | Owns technical accuracy and architecture rules |
| Security lead | Reviews guardrails, data handling, and permission boundaries |
| Developer experience owner | Maintains command reliability and onboarding clarity |
| Repository maintainers | Approve updates as part of normal pull request review |
This keeps the file accurate without adding another meeting to anyone's calendar.
How to tell if it's working
Track these before and after you add the file:
- First-pass acceptance rate — how many agent PRs get merged without major rewrites
- Review cycle time — how long from PR open to approval
- Policy violations — missing tests, unsafe logging, out-of-scope changes
- Rework ratio — how much code reviewers replace after an agent run
- Incident correlation — production regressions from agent-generated changes
If these numbers improve, the file is doing its job.
Repository-specific examples by stack
The structure stays the same across stacks, but the specific rules should match your tools.
Next.js and TypeScript repositories
Useful rules include:
- require strict TypeScript checks before final handoff
- enforce server/client boundary rules in App Router projects
- require accessibility checks for interactive UI changes
- define metadata and SEO requirements for new routes
Python and API repositories
Useful rules include:
- enforce type hints for public interfaces
- require request validation and explicit error handling
- require tests for route handlers and service-layer logic
- prohibit hardcoded secrets and unsafe debug output
Mobile repositories (React Native or Expo)
Useful rules include:
- define platform testing expectations for iOS and Android
- document offline and network-failure handling standards
- require performance checks for high-frequency screens
- define app store release checklist links in the workflow section
These kinds of stack-specific details are what separate a useful file from a generic one.
Starting from scratch
You don't need the whole thing on day one. Build it up over a few weeks.
- Week 1: Add project context, repository map, and command section.
- Week 2: Add coding conventions and pull request workflow requirements.
- Week 3: Add security/compliance guardrails and sensitive-data policies.
- Week 4: Add examples from real agent runs and tighten ambiguous language.
Each week adds a layer, and you'll see results from week one.
Sample policy block for safe autonomous edits
The following example can be inserted into a repository and adjusted to local constraints:
## Autonomous Edit Policy
- Scope: modify only files directly related to the requested task.
- Safety: do not run destructive git commands (`reset --hard`, forced checkout) without explicit approval.
- Validation: run build and test commands before declaring completion.
- Traceability: include changed-file summary and risk notes in final handoff.
- Security: never print secrets or place credentials in source files.
- Unknowns: when behavior is ambiguous, prefer conservative assumptions and document them.
This kind of block works because it's concrete. An agent can follow "run build and test commands before declaring completion" much more reliably than "ensure quality."
Review checklist after each agent run
Quick sanity check for reviewers:
- Were changes limited to the approved scope?
- Did the agent follow repository conventions and naming rules?
- Were tests or build steps executed and reported?
- Are security constraints respected across code, logs, and documentation?
- Is the pull request summary clear about risks and assumptions?
Using this consistently catches most agent mistakes before they hit the main branch.
AI Agent Development
Production-ready AI agents with structured workflows, guardrails, and evaluation pipelines.
Explore serviceCustom Software Development
Engineering teams that ship reliable software with strong conventions and review processes.
Explore serviceFrequently asked questions about AGENTS.md
Is AGENTS.md only useful for large teams?+
No. Small teams actually see the biggest immediate impact because there's less room for miscommunication and every bad PR costs more time.
How often should AGENTS.md be updated?+
Update it whenever architecture, tooling, or release workflows change. A monthly review cadence is usually enough for active repositories.
Can AGENTS.md replace code review?+
No. The file improves first-pass quality, but human review is still required for security, product correctness, and edge-case validation.
What is the fastest way to start?+
Write down your build commands, map your important directories, and list things the agent must never do. You can add coding conventions and PR expectations after your first couple of agent runs.
Bottom line
If you're using AI agents to write code, tell them how your repository works. The teams getting good results from agents aren't using better models. They're giving better instructions.
Start with commands, a repo map, and security rules. Build from there.
agents.md
ai agent configuration
agentic ai standard
ai coding agents
repository governance